Database Design

การเปลี่ยนจาก monolith มาเป็น microservices นั้นสิ่งที่ยากที่สุดคือการเปลี่ยนแนวคิด และหนึ่งในสิ่งที่คุณต้องทำคือการ redesign database ในการเปลี่ยนระบบจากระบบเดิมที่เป็น Monolith ไปเป็น Microservices คือห้ามเอา database เดิมมาใช้เด็ดขาด เนื่องจาก database เดิมนั้นถูกออกแบบมาให้เก็บอยุ่ที่เดียว(Centralize Database) แต่ใน microservices นั้นจะออกแบบเป็น Distributed Database คือแต่ละ service จะมี database เป็นของตัวเองและจะไม่เก็บข้อมูลของคนอื่นเอาไว้กับตัว
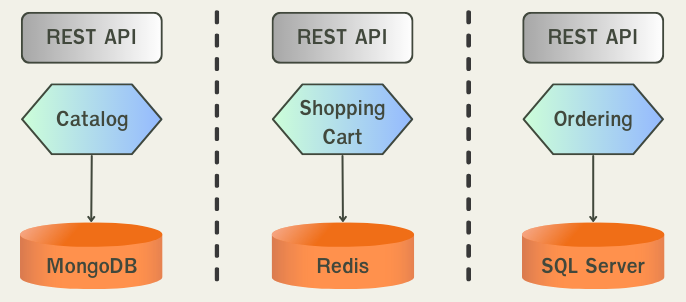
และการที่เราแยก database ของแต่ละ service ออกจากกัน จะทำให้เราสามารถเลือกใช้ database ต่างประเภทกันได้ เช่น product catalog เราอาจเลือกใช้ mongodb เพื่อรองรับการ query ข้อมูลในปริมาณมากๆ แต่เราจะใช้ postgresql ที่เป็น relational database มาจัดการเรื่อง transaction ใน order service
ซึ่งการเลือกใช้ database ให้เหมาะสมกับการทำงานในแต่ละ service เราจะเรียกว่า Polygot Persistance และการเลือกใช้ programming language ให้เหมาะสมกับงานเราจะเรียกว่า Polygot Programming
Database มีกี่ประเภท
ในปัจจบันเราแบ่งกลุ่มของ database ตามประเภทของข้อมูลที่นำมาใส่ โดยจะแยกออกเป็นประเภทต่างๆ ดังนี้
-
Relational Database เราจะใช้ Relational database กับงานที่ต้องการ transaction เนื่องจากใน RDBMS มี ACID(Atomic, Consistency, Isolation, Durability)
-
Document Database เป็น database ที่ทำการจัดเก็บ collection ของ objects จึงเหมาะกับข้อมูลที่มีความเป็น object มากๆ เช่น product catalog
-
Key-Value Data Store เป็น database ที่ใช้ key ในการค้นหาข้อมูลเหมาะสำหรับพวก configuration หรือ state ของระบบอย่าง shopping cart
-
Columnar Database เป็น database ที่จัดเก็บข้อมูลตาม query ที่จะเข้ามาเหมาะสำหรับ data ที่มีขนาดใหญ่(big data) ที่ต้องการนำไปทำ data analytics
-
Time-Series Database เป็น database ที่ใช้เวลาเป็น key ในการดึงข้อมูล เหมาะสำหรับข้อมูลที่เกี่ยวข้องกับ event หรือการ monitoring
-
Graph Database เป็นฐานข้อมูลที่จะเก็บความสัมพันธ์ของข้อมูล แต่ไม่ได้เป็นลำดับชั้น เช่น recommendation(สินค้าแนะนำ หรือหนังที่แนะนำ) สินค้าแต่ละตัวจะเกี่ยวข้องกับใครก็ได้
ถ้าเราเลือก database ได้เหมาะกับลักษณะของข้อมูลที่จะนำมาเก็บ ก็จะทำให้เรา query ข้อมูลได้อย่างรวดเร็ว
5 Common Patterns สำหรับ Microservices Database Design
เวลาที่เราแยก database ออกไปตามแต่ละ services สิ่งที่เราจะต้องเจอคือปัญหาของการ shared data ระหว่าง service และการจัดการกับ transactions โดยที่ใน Microservices Architecture จะมี patterns ที่นำมาใช้งานกับ database ดังนี้
-
The Database-per-Service pattern เป็นหลักการของการออกแบบ microservices ตั้งแต่เริ่มต้นอยู่แล้ว นั่นคือเราจะแยก service แต่ละตัวให้เป็นอิสระต่อกันอย่างเด็ดขาด ดังนั้นเราจะมี 1 service ต่อ 1 database หรือในบางกรณีอาจมีมากกว่า 1 database ก็ได้
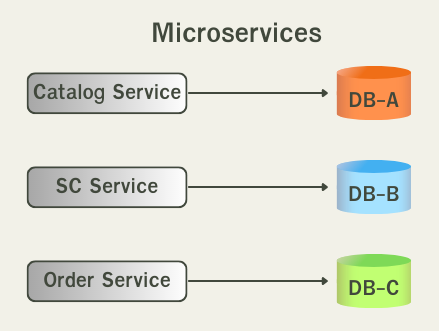
Database per Service pattern และการเลือกใช้ Database per Service pattern จะทำให้เกิด Polygot Persistance ได้ง่ายที่สุด
-
The API Composition pattern ในหลายๆครั้งเราต้องการข้อมูลจากหลายๆ service มารวมกันดังนั้น เราจะใช้ pattern นี้ในการรวบรวม data จากหลายๆ service มาให้เรา เช่น เราจะมี aggregator ในการดึงข้อมูลราคาสินค้าจาก product service และดึงส่วนลดจาก promotion service แล้วนำราคาสินค้าหลังหักส่วนลดแล้วใสลงไปใน shopping cart ดังรูป
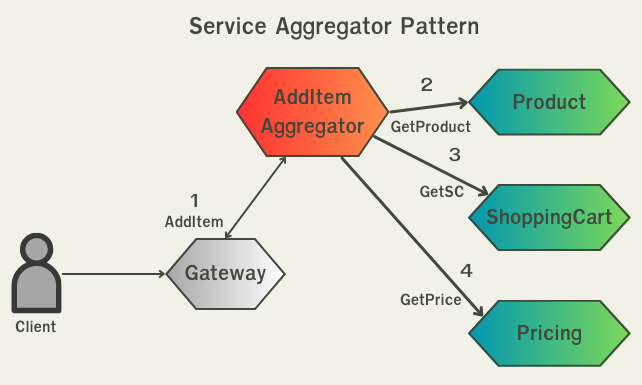
API Composition pattern -
The CQRS pattern CQRS ย่อมาจาก Command Query Responsibility Segregation โดยที่ใน pattern นี้เราจะทำการแยก database ออกเป็น 2 ตัว ซึ่งตัวนึงจะมีไว้สำหรับอ่านอย่างเดียว และอีกตัวนึงจะใช้สำหรับเขียนอย่างเดียว
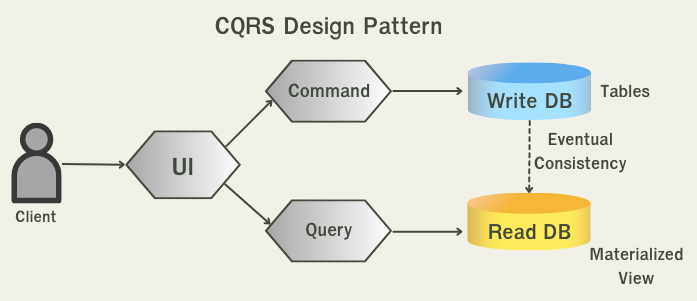
CQRS: Command-Query Responsibility Segregation ซึ่งใน pattern นี้จะมีลักษณะเป็น eventual consistency หมายถึงเราจะไม่ได้ข้อมูลของ database ทั้ง 2 ตัวนี้จะไม่ได้ตรงกัน(consistency) ตลอดเวลา แต่จะใช้ช่วงเวลาสั้นๆในการ sync ข้อมูลระหว่าง databse ทั้ง 2 ตัวนี้
-
The Event Sourcing pattern Event sourcing เป็น pattern ที่เก็บข้อมูลการเปลี่ยนแปลงหรือ event ต่างๆที่เกิดขึ้นใน service นั้นๆ ซึ่งเราจะเก็บไว้ใน event store(database) ข้อมูลที่ทำการจัดเก็บอยู่ใน event store นั้นยจะเป็นหมือน log ที่ใครอยากจะรับรู้การเปลี่ยนแปลงนี้ก็สามารถมา subscribe ไว้ที่ event bus ที่ทำหน้าที่เป็น message broker ได้
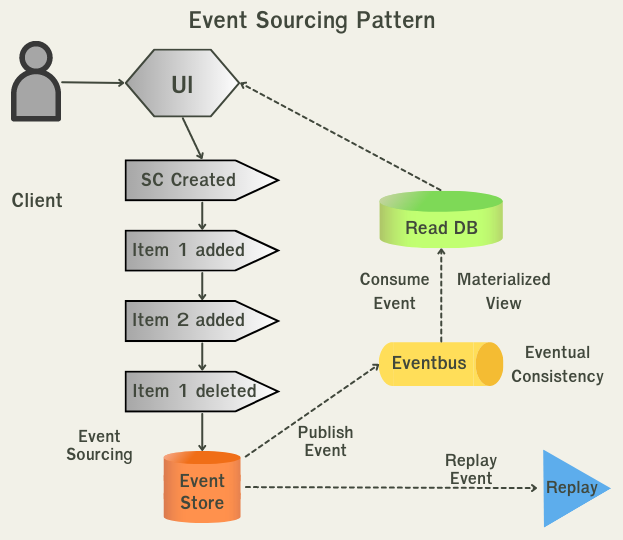
Event sourcing pattern คุณสามารถนำ event ไปทำการ replay ใหม่ได้ถ้าต้องการ เช่นในกรณีที่ service ปลายทางยังไม่ available เราก็จะรอจนกว่า service ปลายทางจะ available แล้วก็ replay event นั้นใหม่ ระบบของเราก็จะมี resilience(ทนทานต่อความเสียหาย) มากขึ้น
-
The Saga pattern เนื่องจาก microservices นั้น design ออกมาเป็น distributed database จึงทำให้การจัดการ transaction นั้นทำได้ค่อนข้างยาก เราจึงต้องใช้ SAGA pattern ในการทำ distributed transaction(ทำ transaction ข้าม service)
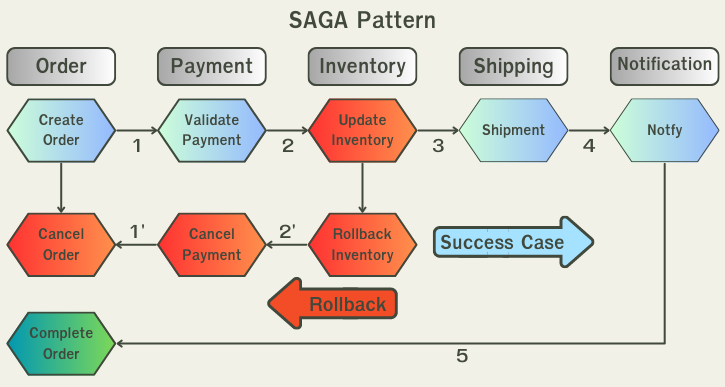
SAGA pattern เราจะทำงานเดินไปข้างหน้า(ลูกศรสีฟ้า) ในสถาณการณ์ปกติ แต่ถ้ามีข้อผิดพลาดเกิดขึ้นเราจำทำการสร้าง compensation request(ลูกศรสีแดง) เพื่อย้อนกลับไปยังจุดเริ่มต้น

Anti pattern สำหรับ Microservices
Anti-pattern คือ pattern หรือ practice ที่จะนำมาซึ่งปัญกาทำให้ความเป็น microservices หรือคุณภาพลดลง ใน Microservices Architecture จะมี 1 Anti-pattern คือ Shared-Database
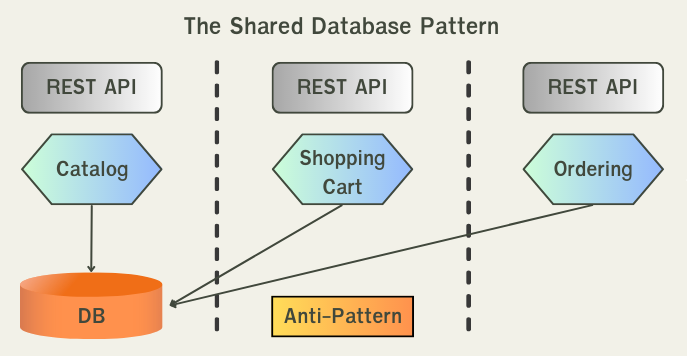
- services นั้นเกิด coupling (ผูกติดกัน) จะทำให้ service ที่ใช้ share database นั้นกลายเป็น unit เดียวกัน ถ้าถอดไปใช้งานที่ไหนก็ต้องถอดออกไปทั้งคู่
- โครงสร้างของ database นั้นจะใหญ่เกินไปเพราะต้องออกแบบให้ใช้ได้กับทุกๆ services
- ถ้าเราแก้โครงสร้างของ databae ก็จะเกิดผลกระทบกับทุกๆ services
- การทดสอบ(testing) ห็จะทำได้ยากขึ้นเพราะ ต้อง test พร้อมกันทุกๆ services
- การ scale ก็จะทำได้ลำบากขึ้น เพราะต้องระวังจะเกิดคอขวด(bottle neck) ที่ database
ยิ่งมีการ Shared Database มากเท่าไหร่ยิ่งทำให้ระบบใกล้เคียงกับการเป็น monolith มากขึ้น

