การใช้งาน AWS S3 Bucket
Object Storage หรือ Object-based Storage คือรูปแบบการเก็บข้อมูลชนิดหนึ่งซึ่งเราจะไม่สามารถแก้ไขส่วนใดส่วนหนึ่งของ Object นั้นได้ ถ้าอยากจะแก้ไขเราต้องนำ Object ใหม่ไปวางทับ Object เดิมอย่างเดียว

AWS S3 คือ Object Storage ที่ให้บริการจัดเก็บไฟล์ ซึ่งสามารถรองรับการเข้าถึง(Read)ไฟล์ ในปริมาณมากๆ และยังสามารถ Scale ได้โดยอัตโนมัติ(พื้นที่ในการเก็บไม่มีขีดจำกัด) แต่ขนาดของไฟล์ที่นำไปวางจะต้องไม่เกิน 5TB แต่ถ้าขนาดเกิน 5 GB เพื่อเพิ่มประสิทธิภาพในการ Upload จะต้องมีการแตกออกเป็นหลายๆไฟล์ อ่านต่อที่นี่
AWS S3 ราคาเท่าไหร่
หลังจากที่คุณสมัคร AWS Account คุณจะได้ Free-tier เป็นระยะเวลา 12 เดือนโดยมีเงื่อนไขดังนี้
- พื้นที่ในการจัดเก็บไฟล์ไม่เกิน 5GB
- 20,000 GET Requests(อ่านไฟล์ไม่เกิน 20,000 ครั้งใน 1 เดือน) ถ้าเกินคุณสามารถใช้ Cloudfront มาช่วยลดปริมาณการอ่านข้อมูลลงได้
- 2,000 PUT Requests(เขียนไฟล์ไม่เกิน 2,000 ครั้งใน 1 เดือน)
หลังจากครบ 12 เดือนหรือมีการใช้งานเกินกว่าที่กำหนด AWS จะคิดค่าใช้จ่ายตามนี้
-
ค่า Storage ตามตารางนี้
ขนาดของ Storage ราคา(ต่อ 1,000 requests) 50 TB แรก 0.92 บาทต่อเดือน 450 TB ต่อไป 0.88 บาทต่อเดือน เกิน 500 TB ขึ้นไป 0.84 บาทต่อเดือน -
ปริมาณการอ่านเขียนข้อมูล
Requests ราคา(ต่อ 1,000 requests) PUT,COPY,POST,LIST(การเขียน) 0.18 บาท GET, SELECT และอื่นๆ 0.015 บาท
ตารางนี้ผมเลือก Region เป็น ap-southeast-1(Singapore) ซึ่งน่าจะใกล้ที่สุดส่วนถ้าต้องการนำไฟล์ไปไว้ใน Region อื่นราคาก็จะแตกต่างจากนี้ และราคานี้จะเป็น S3 Standard ซึ่งเป็นรูปแบบการจัดเก็บข้อมูลแบบ default ซึ่งถ้าคุณต้องการจัดเก็บข้อมูลด้วยรูปแบบ(Storage Class) อื่นๆ ราคาก็จะไม่เท่ากัน ลองเข้าไปดูราคาทั้งหมดได้ที่นี่
เริ่มต้นสร้าง S3 Bucket
ก่อนจะไปดูขั้นตอนการสร้างและใช้งาน S3 Bucket เราต้องเข้าใจความหมายของ 2 คำนี้ก่อน
- Bucket คือ ตระกร้าที่ใช้เก็บข้อมูลเปรียบเทียบได้กับ Database เวลาเรากำหนดค่า Configuration หรือ Policy เข้าไปก็จะมีผลกับทุกๆ Object ที่อยู่ใน Bucket นั้น
- Object คือ ไฟล์และ Metadata ที่ใช้อธิบายไฟล์นั้น ซึ่ง Object จะเป็นสมาชิกที่อยู่ภายใน Bucket จะเปรียบเทียบได้กับ Record ที่อยู่ใน Database นั่นเอง
ขั้นตอนการสร้าง S3 Bucket
เราลองมาดูขั้นตอนการสร้าง S3 Bucket และนำไฟล์ขึ้นไปวางไว้ใน Bucket (Put Object)
-
Login เข้าไปที่ AWS Console
เมื่อ Loging เข้ามาแล้วให้คลิกที่เมนู Services ซ้ายบนและเลือกหัวข้อ S3
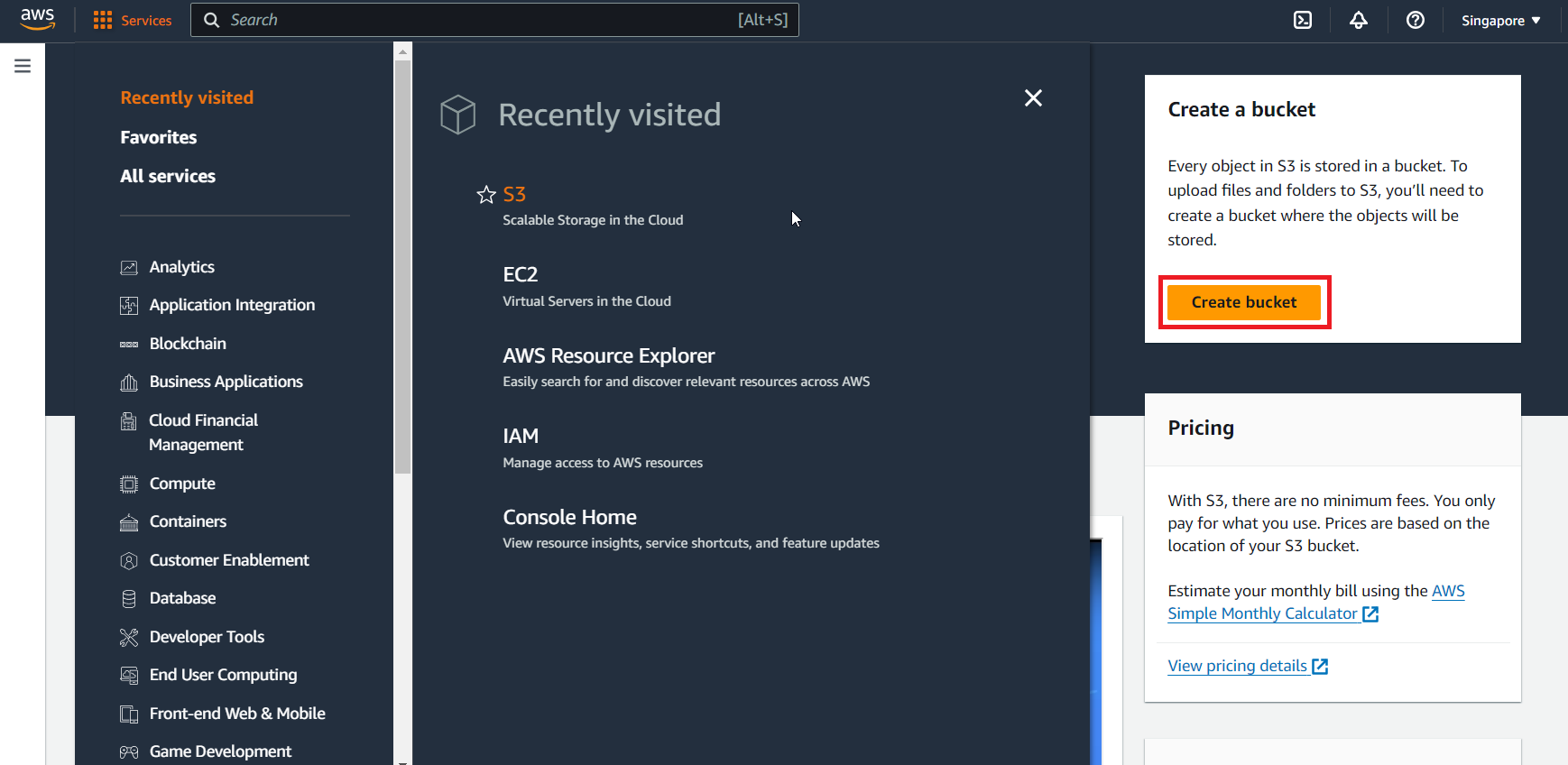
Menu Services > S3 จากนั้นกดปุ่ม Create Bucket ด้านขวามือ
-
ตั้งชื่อของ Bucket ที่ต้องการสร้าง
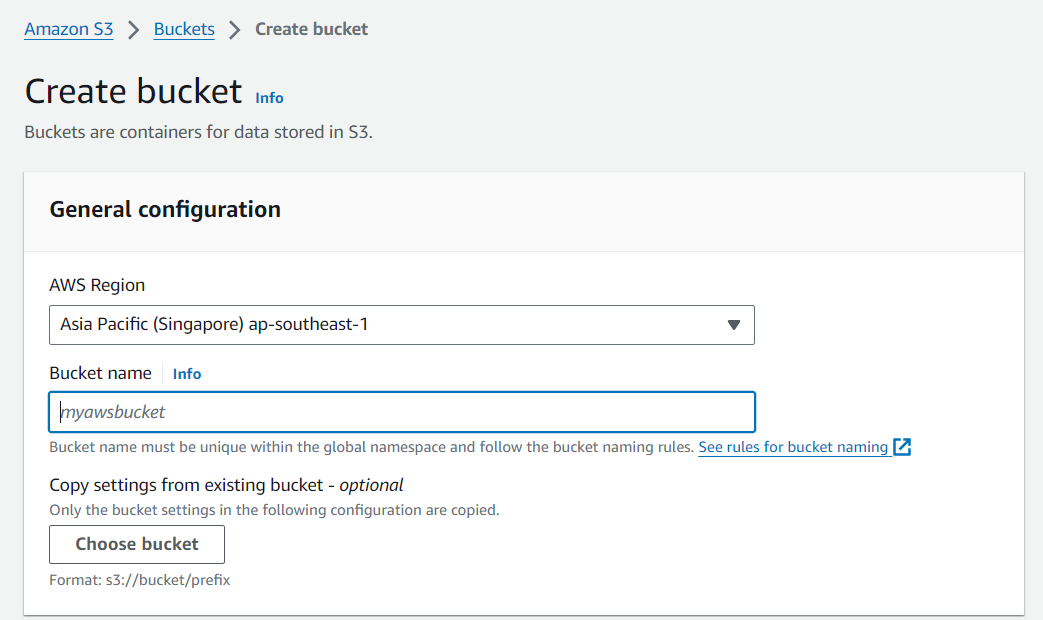
Region เลือกที่ตั้งของ Bucket ที่ต้องการสร้าง โดยควรเลือกภูมิภาคที่ใกล้กับที่ตั้งของเรามากที่สุด เพื่อให้เวลาและต้นทุนที่จะเกิดเหลือน้อยที่สุด
Bucket name การตั้งชื่อ Bucket ต้องเป็น Universal Unique(ห้ามซ้ำกับผู้ใช้อื่นทั่วโลก)
-
เลือก Object Ownership
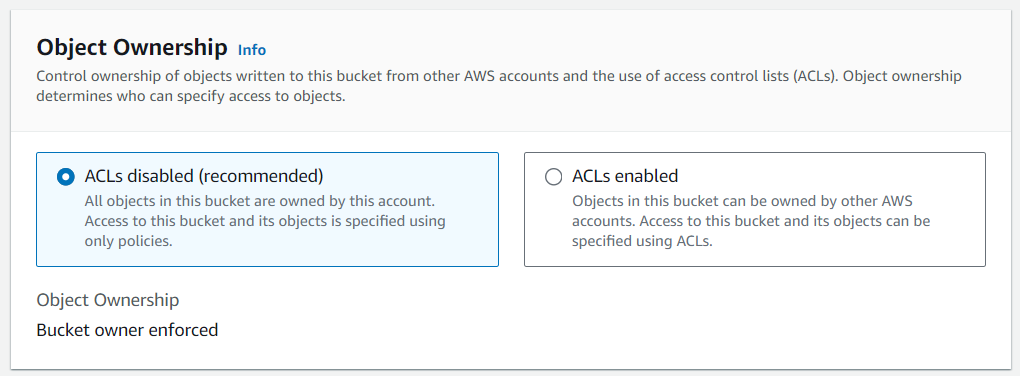
เราสามารถปิดใช้งานหรือเปิดใช้งาน ACLs และควบคุมการเป็นเจ้าของ Object ที่อัปโหลดไปยัง S3 Bucket ได้
-
ตั้งค่า Block Public Access
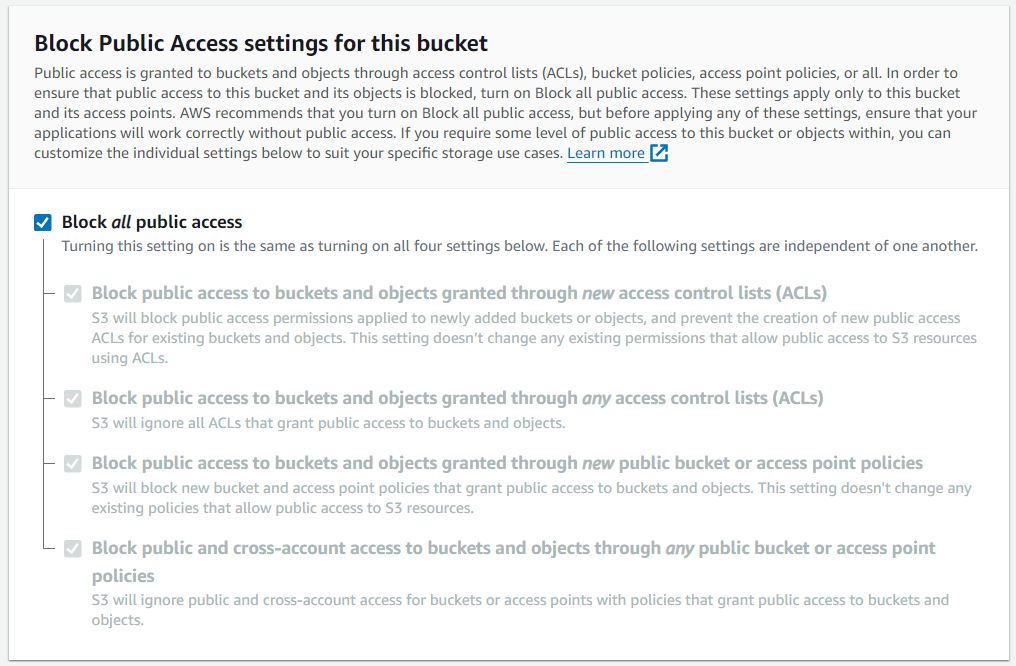
Block Public Access คือการตั้งค่าบล็อกการเข้าถึงสาธารณะที่คุณต้องการใช้กับ Bucket
เราไม่ควรเอา Block Public Access ออกเพราะไฟล์ใน Bucket นี้จะถูกเปิดเผยสู่สาธารณะทันที
-
ตั้งค่า Bucket Versioning
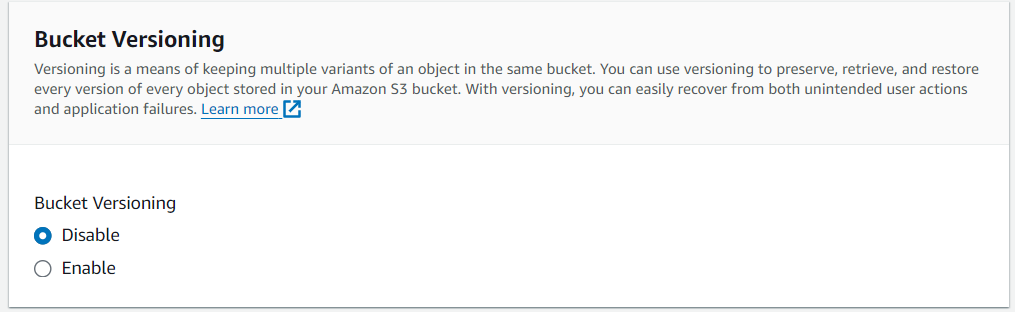
Bucket Versioning เราสามารถเปิดหรือปิด การกำหนด Version สำหรับ Bucket ได้ ตามค่าเริ่มต้น การกำหนดเวอร์ชันจะถูกปิดใช้งานไว้ ซึ่งการตั้งค่าเปิดใช้งานจะเกิดเฉพาะในกรณีที่เราต้องการเก็บ Object หลาย Version ไว้ในที่เก็บข้อมูลเดียวกัน
ถ้าเรามีการเปลี่ยนแปลงข้อมูลอยู่เรื่อยๆ ต้อง Enable Bucket Versioning ขึ้นมาใช้งาน
-
ตั้งค่า Tags
Tags เราสามารถเพิ่ม Tag ลงใน Bucket เพื่อวัตถุประสงค์ต่างๆ เช่น ติดตามต้นทุน Storage, การจัดกลุ่ม Resources และอื่นๆ
-
ตั้งค่า Default encryption
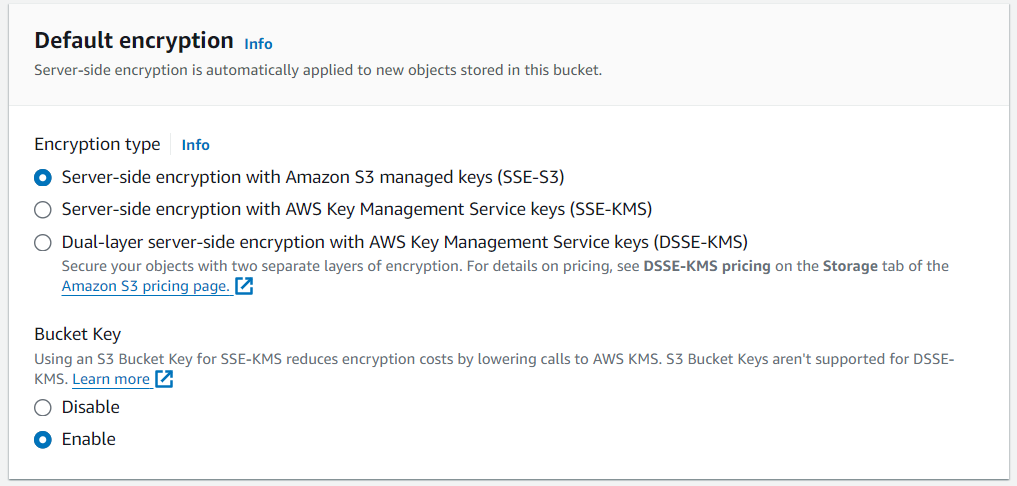
Default encryption เป็นการเข้ารหัสฝั่ง Server สำหรับ Object ที่จะจัดเก็บไว้ใน Bucket โดยมีให้เลือกดังนนี้
- Server-side encryption with Amazon S3 managed keys (SSE-S3)
- Server-side encryption with AWS Key Management Service keys (SSE-KMS)
- Dual-layer server-side encryption with AWS Key Management Service keys (DSSE-KMS)
Bucket Key การใช้ S3 Bucket Key สำหรับ SSE-KMS จะช่วยลด Encryption Costs ที่จะเรียกไปยัง AWS KMS
-
Advanced settings - Object Lock
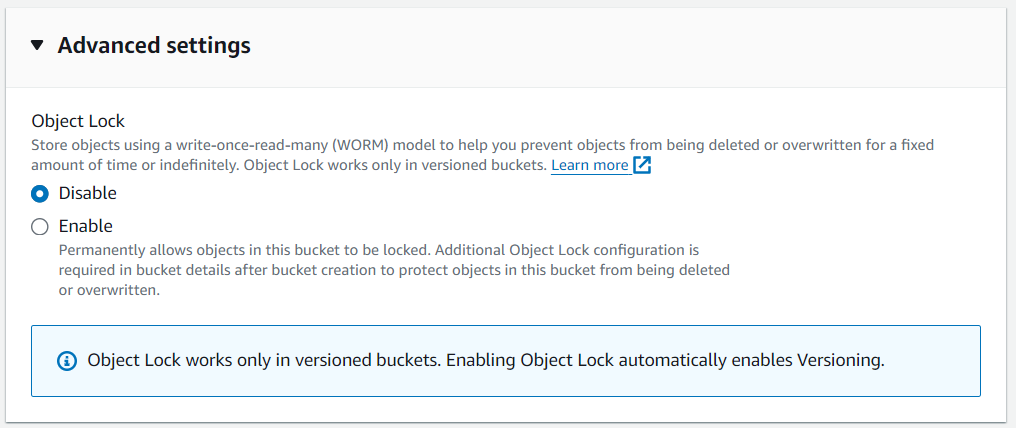
เพียงเท่านี้เราก็จะได้ S3 Bucket มาใช้งาน โดยมีรายละเอียดดังรูป

ขั้นตอนการ Upload File ขึ้นไปยัง S3 Bucket
S3 Bucket จัดเก็บข้อมูลที่เรา Upload ในรูปแบบของ Object ซึ่งจะเป็นอะไรก็ได้ ตั้งแต่ไฟล์เอกสาร ไฟล์รูปภาพ ไฟล์วิดีโอ โฟลเดอร์ และอื่นๆ
-
Upload Files หรือ Folders
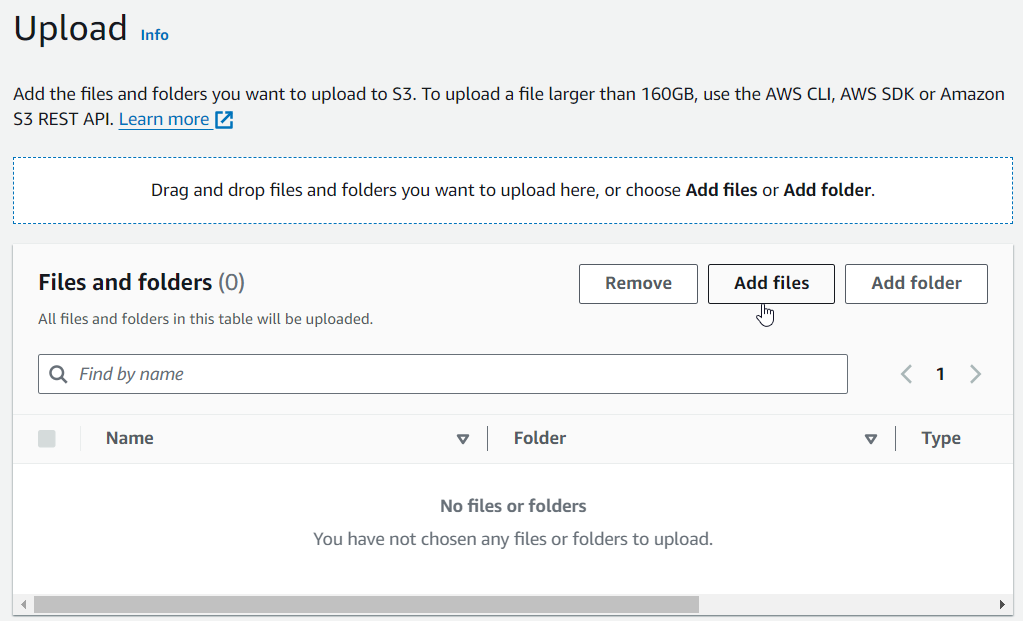
กดปุ่ม Add files และเลือกไฟล์ที่ต้องการอัปโหลด หรือเราสามารถลากและวางไฟล์ลงในหน้าเพื่ออัปโหลดได้โดยตรง
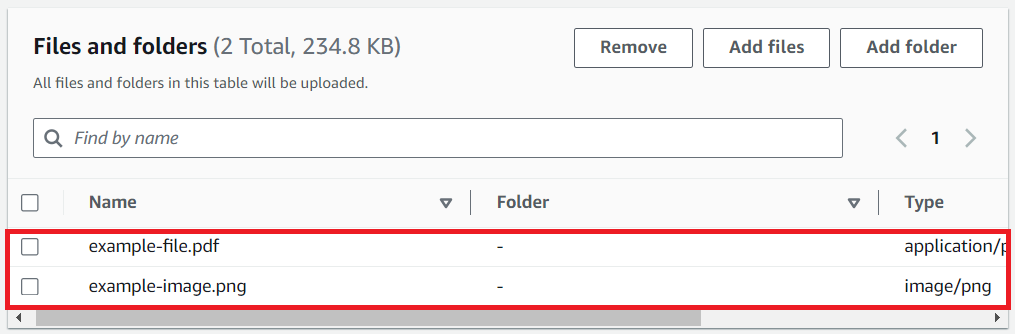
หลังจากเลือกและยืนยันไฟล์ที่จะอัพโหลดผ่าน File explorer หรือผ่าน ลากและวาง ไฟล์ที่เลือกจะแสดงด้านล่าง
-
Upload ไปยัง S3 Bucket เรียบร้อย
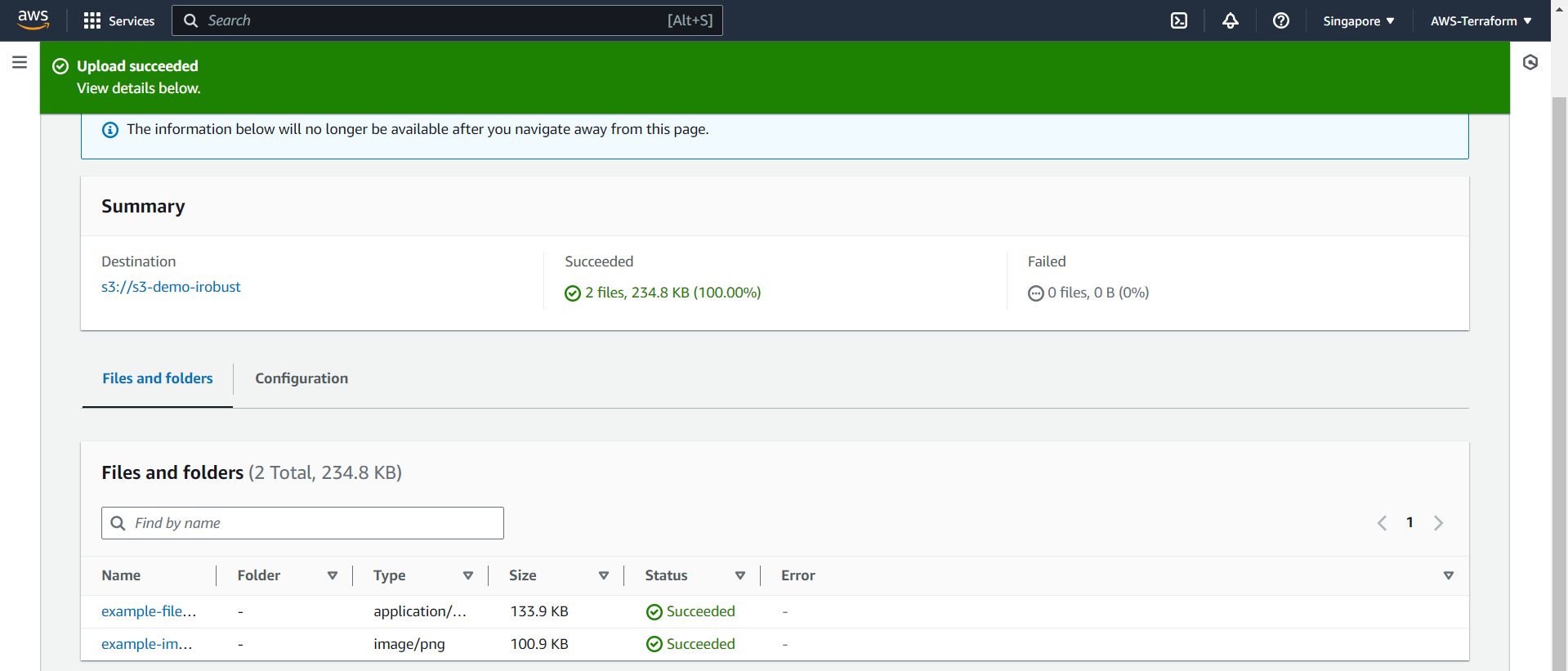
หลังจากคลิกปุ่ม “๊Upload” ที่ด้านล่างของหน้า ไฟล์ที่เลือกจะถูก Upload ไปยัง S3 Bucket
AWS S3 CLI
เราสามารถใช้ AWS CLI เข้าไปจัดการกับ S3 Bucket ได้โดยเราจะแบ่ง Command ของการจัดการ S3 ออกเป็นกลุ่มๆ ดังนี้
จัดการ Buckets
ถ้าต้องการลบ bucket ออกเราจะใช้คำสั่ง
$ aws s3 rb s3://bucket-name --force
List รายชื่อไฟล์ใน S3 Bucket
เราสามารถดึงรายชื่อของ S3 Buckets ออกมาด้วยคำสั่ง
$ aws s3 ls
ถ้าต้องการ list รายชื่อ files หรือ directories ใน S3 Bucket ออกมาเราจะใช้คำสั่ง
$ aws s3 ls s3://bucket-nmae
ถ้าต้องกรลบ files หรือ directory ใน S3 bucket เราจะใช้คำสั่ง
$ aws s3 rm s3://bucket-name/file-name
Upload ไฟล์ขึ้น S3
$ aws s3 cp myfile.txt s3://bucket-name/folder1/
ถ้าต้องการ Upload ทั้ง Folder เราต้องใส่ –recursive เข้าไปแบบนี้
$ aws s3 cp --recursive myfolder s3://bucket-name/folder1/
การ Sync ไฟล์กับ AWS S3
ถ้าต้องการ Download ไฟล์จาก S3 Bucket ลงมาที่เครื่องของเรา ต้องใช้คำสั่ง
$ aws s3 sync s3://bucket-name/ /local-directory
ถ้าต้องการ Upload ไฟล์จาก local ขึ้นไปบน S3 Bucket เราจะใช้คำสั่ง
$ aws s3 sync /local-directiory s3://bucket-name/
/local-directory คือ folder ในเครื่องที่เรา run AWS CLI
การใช้คำสั่ง aws s3 sync จะเป็นการ sync ให้ files และ directories ในเครื่องเราตรงกับ S3 bucket
กำหนดสิทธิการเข้าถึง S3 ด้วย Bucket Policy
การกำหนดสิทธิบน Cloud เราจะกำหนดได้ 2 อย่างคือ
- สิทธิที่กำหนดให้กับ User หรือ Service ที่ผ่าน Authentication เข้ามา
- สิทธิที่กำหนดให้กับ Resource เช่น Bucket Policy
เวลาใช้งาน AWS จะนำสิทธิจากทั้ง 2 ฝั่งมารวมกันแล้วตรงไหนที่เจอ DENY จะชนะเสมอ(ตรงไหนมี DENY จะไม่มีสิทธิเข้าใช้งาน) ตัวอย่างของ AWS Bucket Policy จะเป็นดังนี้
{
"Version": "2012-10-17",
"Id": "PutObjPolicy",
"Statement": [{
"Sid": "DenyObjectsThatAreNotSSEKMS",
"Principal": "*",
"Effect": "Deny",
"Action": "s3:PutObject",
"Resource": "arn:aws:s3:::DOC-EXAMPLE-BUCKET/*",
"Condition": {
"Null": {
"s3:x-amz-server-side-encryption-aws-kms-key-id": "true"
}
}
}]
}
ในตัวอย่างนี้จะเป็นการกำหนดให้ file ที่จะเขียนลงใน Bucket นั้นต้องถูก Encrypted ด้วย AWS managed Key(ใช้ key ชื่อ aws/s3) เท่านั้น ซึ่งจะเรียกวิธีการเข้ารหัสแบบนี้ว่า Server Side Encryption โดยใช้ AWS Managed Key(SSE-KMS)
องค์ประกอบของ Bucket Policy
การอ่านหรือเขียน Bucket Policy ต้องเข้าใจ 4 องค์ประกอบนี้
- Effect กำหนดว่า Policy นี้เป็นการ Allow หรือ Deny
- Principals ระบุถึง User หรือ Service ที่ต้องสามารถเข้าได้(Allow) หรือเข้าไม่ได้(Deny)
- Action สิทธิในการทำงานกับ Bucket เช่น ListBucket, GetObject หรือ PutObject
- Condition เงื่อนไขว่าจะ Allow หรือ Deny ด้วย Condition Operators ต่างๆ เช่น StringEquals, NumericLessThanEquals หรือ StringLike
ส่วน Statement ID(Sid) เป็นชื่อที่เราตั้งให้กับ Policy เราจะตั้งชื่ออะไรก็ได้ขอแค่อย่าให้ซ้ำกับ Policy อื่นๆ
เราสามารถสร้าง Bucket Policy ผ่านทางหน้า UI โดยเข้าไปที่ AWS Policy Generator
S3 Storage Class
AWS S3 นั้นมี Storage ให้เราเลือกหลายประเภทซึ่งจะแยกตามความถี่ของการอ่านเขียนข้อมูล โดย S3 จะมี Storage Class ดังนี้
-
S3 Standard เป็นรูปแบบการจัดเก็บข้อมูลแบบ default เหมาะสำหรับการอ่านเขียนข้อมูลบ่อยๆ เช่น Website หรือ Log file ซึ่ง S3 Standard จะมีการ Replicate ข้อมูลไว้มากกว่า 3 AZ(Availability Zone) ทำให้ S3 Standard
S3 Standard มี Availability อยู่ที่ 99.99%
-
S3 Standard-Infrequent Access(S3 Standard-IA) จะเหมาะกับข้อมูลที่ไม่ค่อยมีการอ่านเขียน แต่เมื่อเราอยากได้ข้อมูลเมื่อไหร่ก็ต้องได้ตามต้องการ ราคาของ Storage แบบนี้จะถูกกว่า S3 Standard เหมาะสำหรับข้อมูลที่ Backup ไว้เพื่อทำ Diaster Recovery
S3 Standard-IA มี Availability อยู่ที่ 99.9%
-
S3 One Zone-Infrequent Access จะเหมือนกับ S3 Standard-IA แต่จะเก็บไว้แค่ AZ เดียว เหมาะกับข้อมูลที่ไม่ได้มีความสำคัญมากถ้าหายไปก็ไม่ได้ส่งผลเสียมากมาย ซึ่งราคาจะถูกกว่า S3 Standard-IA อยู่ ประมาณ 20%
S3 One Zone-IA มี Availability อยู่ที่ 99.5%
-
S3 Glacier เป็น Storage สำหรับการ Backup ในระยะยาว เพราะราคาของ S3 Glacier จะถูกมากๆเมื่อเทียบกับ Storage Class อื่นๆ แต่จะคิดเงินทุกครั้งที่มีการอ่านข้อมูล ดังนั้น S3 Glacier จะเหมาะกับข้อมูลที่ต้องการพื้นที่เยอะ แต่มีการอ่านออกมาใช้งานน้อยๆ
S3 Glacier จะแบ่ง Storage Class ออกเป็น 3 ประเภทย่อยๆ คือ
- S3 Glacier Instance Retrival จะเป็น Storage Class ที่ราคาถูกกว่า S3 One Zone-Infrequent Access แต่จะคิดค่าใช้จ่ายตามการอ่านข้อมูล
- S3 Glacier Flexible Retrival จะราคาถูกกว่า S3 Glacier Instance Retrival แต่ตอน Recovery อาจใช้เวลาตั้งแต่ 1 นาทีไปจนถึง 12 ชั่วโมงเลยทีเดียว
- S3 Glacier Deep Archive ราคาถูกที่สุดแต่ตอน Recovery อาจต้องใช้เวลา 12-48 ชั่วโมง
S3 Glacier ทั้งแบบ Flexible Retrival และ Deep Archive จะทำให้ Recovery Time Objective(RTO) สูงขึ้นมากๆ
การเลือกใช้ Storage Class นั้นเราสามารถทำได้ 2 วิธีคือ
- เลือก Default Storage Class ตอนสร้าง S3 Bucket
- เลือก Storage Class ได้ด้วยการส่ง Header x-amz-storage-class เข้าไปตอน PutObject เข้าไปใน S3 Bucket(Upload ไฟล์)
Storage Lifecycle
จาก Storage Class แต่ละแบบ จะเห็นว่าเราจะใช้ Storage Class ต่างกันในแต่ละ Phase ของ Data Lifecycle เช่น ช่วงที่เราใช้ข้อมูลบ่อยๆ เราจะเก็บข้อมูลไว้ใน S3 Standard แต่ถ้าเริ่มไม่มีการใช้แล้วอาจเปลี่ยนไปเป็น S3 Standard-IA ก็ได้ ซึ่งเราสามารถเลือก Storage Class ได้ 2 วิธีคือ
- ใช้ S3 Intelligent Tiering
- กำหนด Lifecycle Rule
S3 Intelligent Tiering
S3 จะมี S3 Intelligent-Tiering เป็นเครื่องมือที่จะช่วยเลือก Storage Class ที่เหมาะสมให้เรา โดย S3 Intelligent-Tiering จะสร้าง Storage ทั้ง 3 แบบ(S3 standard, S3 Standard-IA และ S3 One Zone-IA) และ Copy ข้อมูลไปไว้ใน Storage Class ที่เหมาะสมกับความถี่ในการอ่านข้อมูล
S3 Intelligent Tiering จะเป็นเครื่องมือที่คอยย้าย Storage ให้เราโดยอัตโนมัติ
S3 Lifecycle Rule
เราสามารถกำหนดเงื่อนไขของการเปลี่ยน Storage Class ได้โดย
- เลือก Bucket ที่ต้องการ
- เลือก Management tab
- กดปุ่ม Create Lifecycle Rule
- เลือก Move current versions of object between storage classes
- กำหนด Storage Class ที่ต้องการย้ายไป และระบุจำนวนวัน(นับจากวันที่นำ Object ขึ้นไปไว้ใน Bucket) เราสามารถเพิ่ม Transition ได้เรื่อยๆ
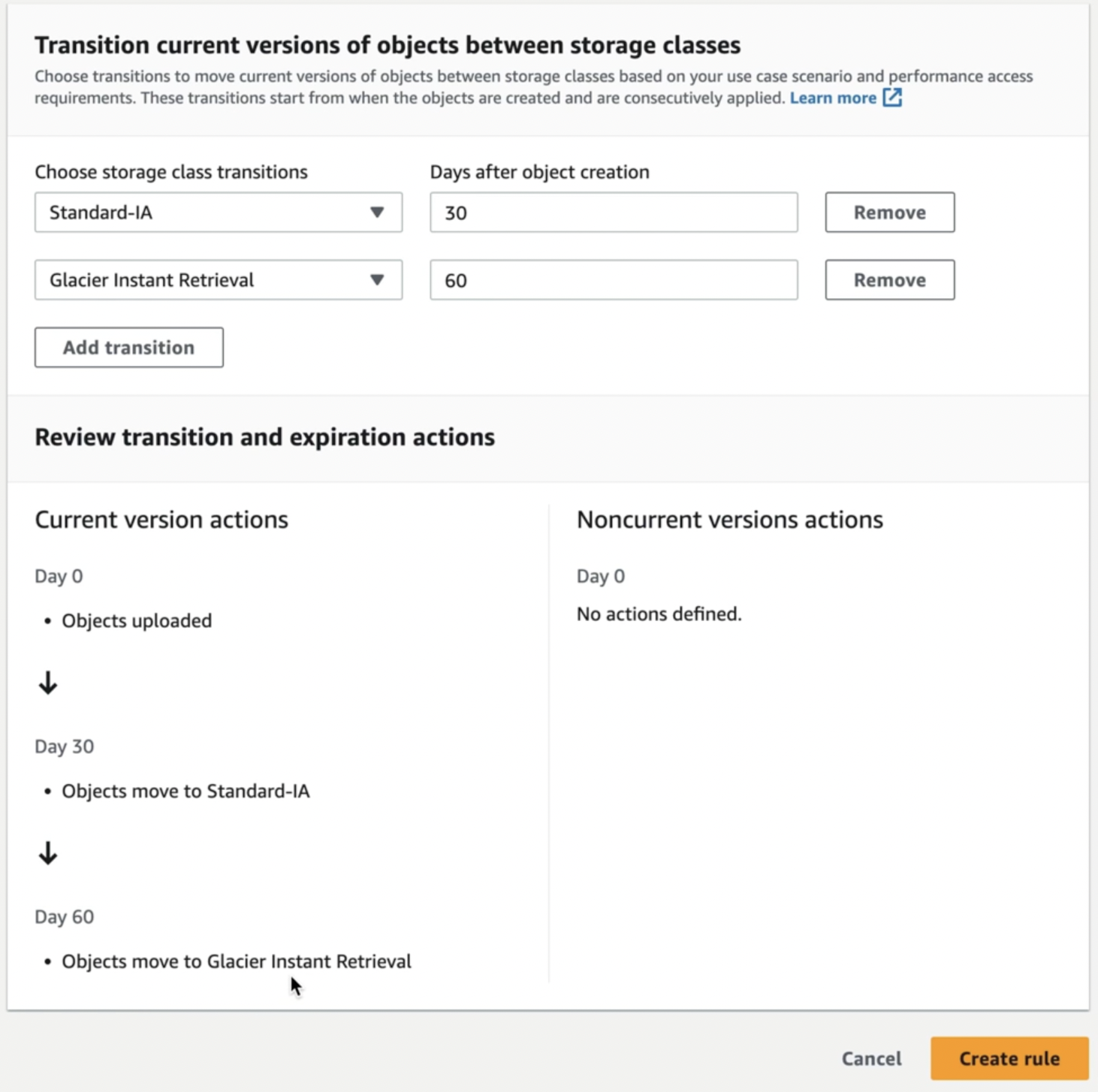
สร้าง S3 Lifecycle Rule - กดปุ่ม Create rule
AWS S3 Performance
การที่เรานำไฟล์ไปไว้ใน S3 Buckets เราจะได้ Performance ตามนี้
- เราจะได้ Byte แรกภายใน 100-200 milliseconds
- Requests PUT/COPY/POST/DELETE ได้ 3,500 requests/sec
- Requests GET/HEAD ได้ 5,500 requests/sec
S3 Prefix
การจัดการ Performance ของ S3 จะแบ่งตาม S3 Prefix ซึ่ง S3 Prefix คือข้อความที่อยู่หลังชื่อ Bucket ไปจนถึงชื่อ Folder ที่อยู่ในสุด ยกตัวอย่างเช่น
S3 Prefix คือชื่อ Folder ที่อยู่ใน Bucket เช่น
- mybucket/folder1/subfolder1/myfile.jpg จะมี prefix เป็น folder1/subfolder1
- mybucket/folder2/subfolder1/myfile.jpg จะมี prefix เป็น folder2/subfolder1
- mybucket/folder3/myfile.jpg จะมี prefix เป็น folder3
นั่นหมายความว่าถ้าเรายิ่งแบ่ง Folder มากเท่าไหร่เราจะได้ Performance ที่ดีมากขึ้น
ตรงไหนที่มีการอ่านหรือเขียนไฟล์บ่อยๆ ให้เราแยก Folder ออกมา เพราะถ้าเมื่อเราแยก Folder ออกมา Prefix ของเราจะเป็นคนละตัว เช่น ถ้าเราแบ่งไฟล์ออกไปเก็บไว้ใน Folder ทั้งหมด 3 Folders เราจะได้ Performace เป็น GET หรือ HEAD methods ได้ 16,500(5,500 x 3) requests/sec เนื่องจากทั้ง 3 Folders นี้จะมี Prefix ไม่เหมือนกัน
Performance บน Encrypted Data
ในกรณีที่ Data ใน S3 bucket นั้นมีการ Encryption ตอน Upload หรือ Download ข้อมูลจะต้องมีการนำ Key ที่อยู่ใน Key Management Service(KMS) มาใช้งาน ดังนั้น KMS จะมีการกำหนดปริมาณการใช้งาน(Rate Limiting) ซึ่งจะแตกต่างกันไปตาม Region ต่างๆ ซึ่งอาจเป็น 5,500, 10,000 หรือ 30,000 requests/sec
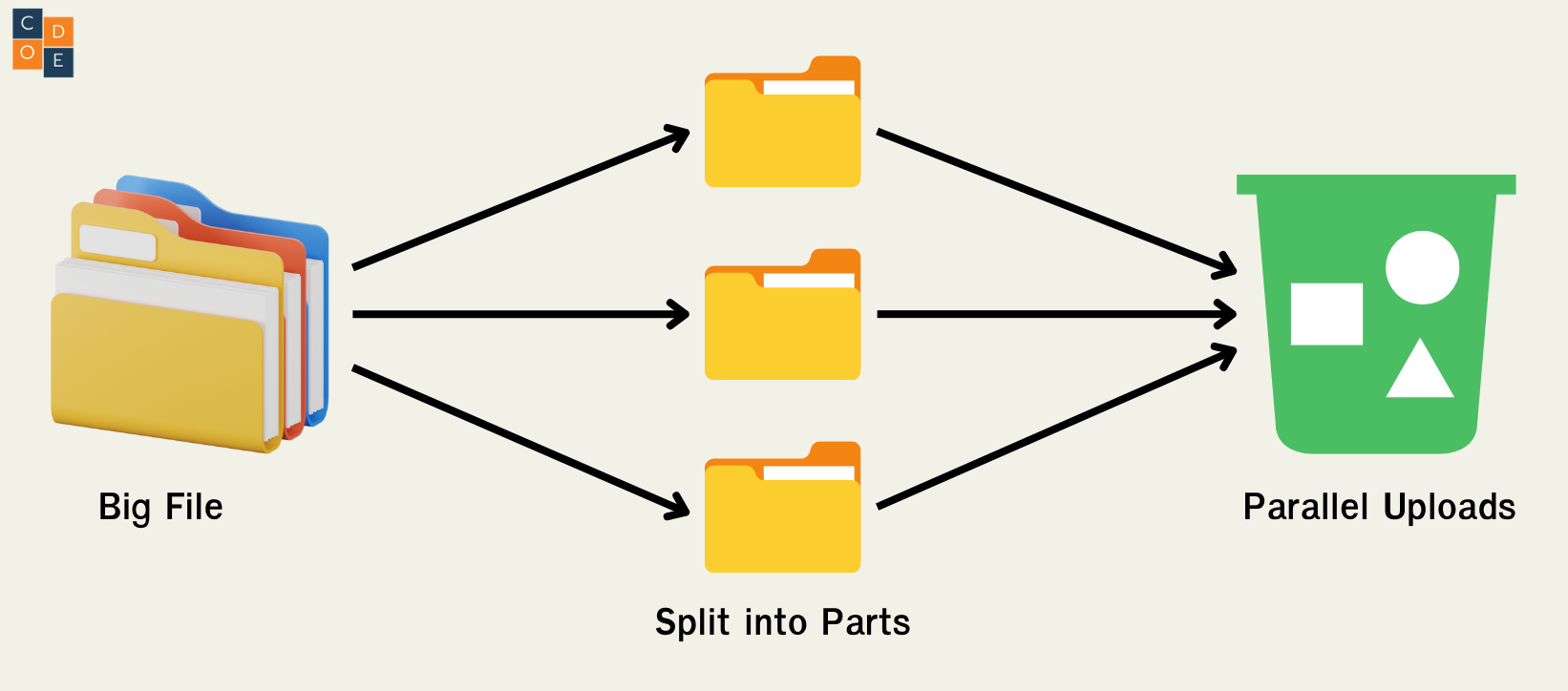
เพิ่ม Performance ให้กับการ Upload ไฟล์
เมื่อเราต้องการ Upload file ขึ้น S3 เราสามารถแบ่งไฟล์ออกเป็น ไฟล์เล็ก แล้ว Upload ขึ้นไปแบบ Parallel โดยที่
- AWS แนะนำ(Recommended)ให้แบ่งไฟล์ออกเป็นไฟล์เล็กๆ เมื่อขนาดของไฟล์เกิน 100 MB
- AWS บังคับ(Must)ให้เราแบ่งไฟล์ออกเมื่อ ไฟล์มีขนาดเกิน 5 GB